Please bear with me as this is literally the first major code I have ever written and its for OpenAI's ChatGPT API.
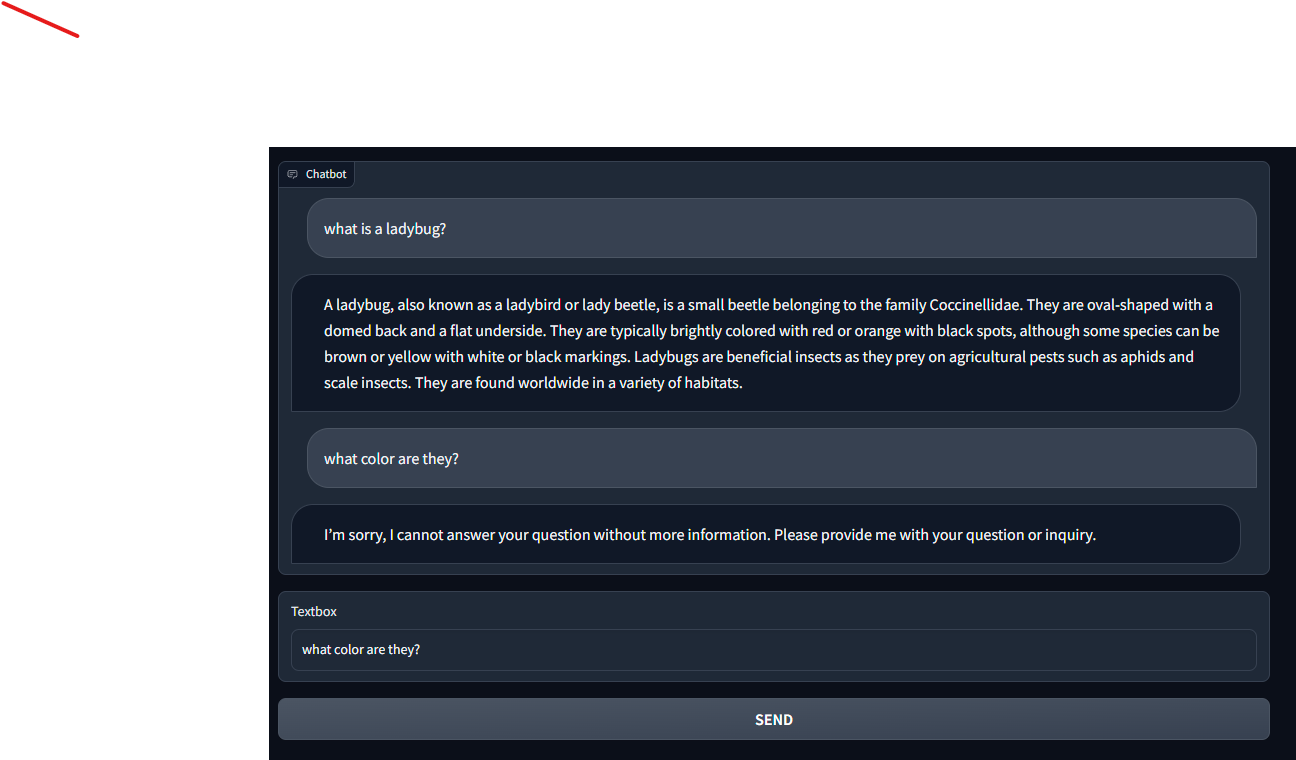
What I intend to do with this code is load a pdf document or a group of pdf documents. Then split them up so as to not use up my tokens. Then the user would ask questions related to said document(s) and the bot would respond. The thing I am having trouble with is that I want the bot to understand context as I ask new questions. For instance: Q1: What is a lady bug? A1: A ladybug is a type of beetle blah blah blah.... Q2: What color are they? A2: They can come in all sorts of colors blah blah blah... Q3: Where can they be found? A3: Ladybugs can be found all around the world....
But I cannot seem to get my code up and running. Instead, this is the output I get: What I get when I ask a follow up question that requires the bot to know context
{kind=link}
**Here is the code: **
import os
import platform
import openai
import gradio as gr
import chromadb
import langchain
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import TokenTextSplitter
from langchain.document_loaders import PyPDFLoader
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
#OpenAI API Key goes here
os.environ["OPENAI_API_KEY"] = 'sk-xxxxxxx'
#load the data here.
def get_document():
loader = PyPDFLoader('docs/ladybug.pdf')
data = loader.load()
return data
my_data = get_document()
#converting the Documents to Embedding using Chroma
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=50)
my_doc = text_splitter.split_documents(my_data)
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(my_doc, embeddings)
retriever=vectordb.as_retriever(search_type="similarity")
#Use System Messages for Chat Completions - this is the prompt template
template = """{question}"""
QA_PROMPT = PromptTemplate(template=template, input_variables=["question"])
#QA_PROMPT = PromptTemplate(template=template, input_variables=["question"])
# Call OpenAI API via LangChain
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
#input_key="question",
def generate_response(query,chat_history):
if query:
llm = ChatOpenAI(temperature=0.5, model_name="gpt-3.5-turbo")
my_qa = ConversationalRetrievalChain.from_llm(llm, retriever, QA_PROMPT, verbose=True, memory=memory)
result = my_qa({"question": query, "chat_history": chat_history})
return result["answer"]
# Create a user interface
def my_chatbot(input, history):
history = history or []
my_history = list(sum(history, ()))
my_history.append(input)
my_input = ' '.join(my_history)
output = generate_response(input,history)
history.append((input, output))
return history, history
with gr.Blocks() as demo:
gr.Markdown("""<h1><center>GPT - ABC Project (LSTK)</center></h1>""")
chatbot = gr.Chatbot()
state = gr.State()
text = gr.Textbox(placeholder="Ask me a question about the contract.")
submit = gr.Button("SEND")
submit.click(my_chatbot, inputs=[text, state], outputs=[chatbot, state])
demo.launch(share = True)
I have no idea what I can try and everytime I try something, I manage to make it worse. so I left it as is in hopes someone here can help.
Many thanks in advance.