I am currently reading C++ Concurrency in Action by Anthony Williams. One of his listing shows this code, and he states that the assertion that z != 0 can fire.
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x()
{
x.store(true,std::memory_order_release);
}
void write_y()
{
y.store(true,std::memory_order_release);
}
void read_x_then_y()
{
while(!x.load(std::memory_order_acquire));
if(y.load(std::memory_order_acquire))
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire));
if(x.load(std::memory_order_acquire))
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0);
}
So the different execution paths, that I can think of is this:
1)
Thread a (x is now true) Thread c (fails to increment z) Thread b (y is now true) Thread d (increments z) assertion cannot fire
2)
Thread b (y is now true) Thread d (fails to increment z) Thread a (x is now true) Thread c (increments z) assertion cannot fire
3)
Thread a (x is true) Thread b (y is true) Thread c (z is incremented) assertion cannot fire Thread d (z is incremented)
Could someone explain to me how this assertion can fire?
He shows this little graphic:
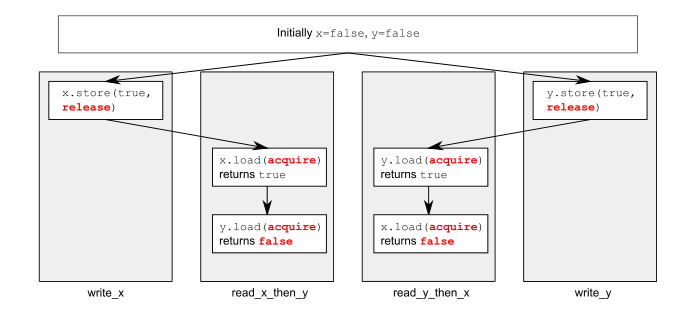
Shouldn't the store to y also sync with the load in read_x_then_y, and the store to x sync with the load in read_y_then_x? I'm very confused.
EDIT:
Thank you for your responses, I understand how atomics work and how to use Acquire/Release. I just don't get this specific example. I was trying to figure out IF the assertion fires, then what did each thread do? And why does the assertion never fire if we use sequential consistency.
The way, I am reasoning about this is that if thread a (write_x) stores to x then all the work it has done so far is synced with any other thread that reads x with acquire ordering. Once read_x_then_y sees this, it breaks out of the loop and reads y. Now, 2 things could happen. In one option, the write_y has written to y, meaning this release will sync with the if statement (load) meaning z is incremented and assertion cannot fire. The other option is if write_y hasn't run yet, meaning the if condition fails and z isn't incremented, In this scenario, only x is true and y is still false. Once write_y runs, the read_y_then_x breaks out of its loop, however both x and y are true and z is incremented and the assertion does not fire. I can't think of any 'run' or memory ordering where z is never incremented. Can someone explain where my reasoning is flawed?
Also, I know The loop read will always be before the if statement read because the acquire prevents this reordering.
memory_order_seq_cstto avoid the assertion. – Joby" does not mean this write is visible in the current thread. – Kolivas