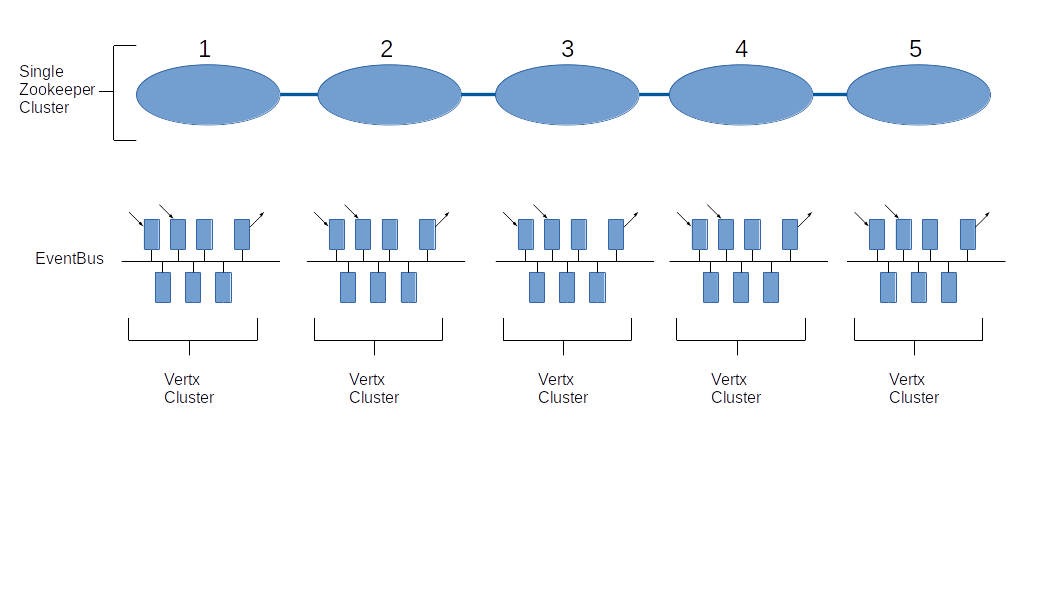
I've now had time to review each of the alternatives Vertx directly supports as a 'cluster manager' (Hazelcast, Zookeeper, Ignite, Infinispan) and we're proceeding with a Zookeeper architecture for our system, replacing Hazelcast:
![Zookeeper / Vertx multi-server architecture]()
Here's the background to our decision:
We started as a fairly typical (if there is such a thing) Vertx development with multiple verticles in a JVM responding to external events (urban sensor data entering our java/vertx feed handlers) published on the eventbus and the data being processed asynchronously in many other vertx verticles, often involving them publishing new derived data as new asynchronous messages.
Quite quickly we wanted to use multiple JVM's, mainly to isolate the feedhandlers from the rest of the code so if things broke the feedhandlers would keep running (as a failsafe they're persisting the data as well as publishing it). So we added (easily) Vertx clustering so the JVM's on the same machine could communicate and all verticles could publish/subscribe messages in the same system. We used the default cluster manager, Hazelcast, and modified the config so the vertx clustering is limited to the single server (we run multiple versions of the entire platform on different servers and don't want them confusing each other). We have hundreds of verticles in half-a-dozen JVM's.
Our environment (search SmartCambridge vertx) is fairly dynamic with rapid development cycles (e.g. to create a new feedhandler and have it publishing its data on the eventbus) and that means we commonly wish to start up a JVM containing these new verticles and have it join an existing vertx cluster, maybe permanently, maybe just for a while. Vertx/Hazelcast has joining a (vertx) cluster as a fairly serious operation, i.e. Hazelcast has (I believe) a concept of Hazelcast cluster members and Hazelcast clients, where clients can come and go easily but joining a Hazelcast cluster as a member requires considerable code compatibility between the existing cluster and the new member. Each time we upgraded our Vertx library the Hazelcast library version would change and this made it impossible for a newly compiled vertx verticle to join an existing vertx cluster.
Note we have experimented with having the Vertx eventbus flow between multiple servers, and also extend the eventbus into the browser/javascript, but in both cases have found it simpler/more robust to be explicit about routing messages from server to server and have written verticles specifically for that purpose.
So the new plan (after several years of Vertx development), given our environment of 5 production/development servers but with the vertx eventbus always limited to single servers, is to implement a single Zookeeper cluster across all 5 servers so we get the Zookeeper native resilience goodness, and configure each production server to use a different znode root (the default is 'io.vertx' but this is a simple config option).
This design has an attractive simple minimum build on a single server (i.e Zookeeper + Vertx) so ad-hoc development on a random machine (e.g. laptop) is still possible but we can extend our platform to have multiple servers in a single vertx cluster trivially by setting a common znode root.