Can x86 reorder a narrow store with a wider load that fully contains
it?
Yes, x86 can reorder a narrow store with a wider load that fully contains it.
That is why your lock algorithm is broken, shared_value isn't equal to 800000:
GCC 6.1.0 x86_64 - link to assembler code: https://godbolt.org/g/ZK9Wql
Clang 3.8.0 x86_64 - link to assembler code: https://godbolt.org/g/qn7XuJ
See below correct example.
The question:
The ((INT8*)lock)[ 1 ] = 1; and ((INT8*)lock)[ 5 ] = 1; stores aren't to
the same location as the 64bit load of lock. However, they are each
fully contained by that load, so does that "count" as the same
location?
No, that does not.
Intel® 64 and IA-32 Architectures Software Developer’s Manual says:
8.2.3.4 Loads May Be Reordered with Earlier Stores to Different Locations The Intel-64 memory-ordering model allows a load to be
reordered with an earlier store to a different location. However,
loads are not reordered with stores to the same location.
This is a simplified rule for the case when the STORE and LOAD of the same size.
But a general rule is that the write into the memory is delayed for a time, and STORE (address+value) enqueued to the Store Buffer to waits cache-line in exclusive-state (E) - when this cache line will be invalidated (I) in cache of other CPU-Cores. But you can use asm operation MFENCE (or any operation with [LOCK] prefix) to forced wait until the write is done, and any following instructions can be done only after the Store Buffer will have been cleared, and STORE will be visible to all CPU-Cores.
About reordering two lines:
((volatile INT8*)lock)[threadNum] = 1; // STORE
if (1LL << 8*threadNum != *lock) // LOAD
If STORE and LOAD size is equal, then LOAD CPU-Core do (Store-forwarding) lookup into Store-Buffer and sees all the required data - you can get all actual data right now before STORE has been done
If STORE and LOAD size is not equal, STORE (1 Byte) and LOAD (8 Byte), then even if LOAD CPU-Core do lookup into Store-Buffer then it sees only 1/8 of the required data - you can't get all actual data right now before STORE has been done. Here could be 2 variants of CPU actions:
case-1: CPU-Core loads other data from cache-line which in shared-state (S), and overlaps 1 Byte from Store Buffer, but the STORE still remains in the Store Buffer and waits for receipt of an exclusive-state (E) cache line to modify it - i.e. CPU-Core reads data before STORE has been done - in your example is data-races (error). STORE-LOAD reordered to LOAD-STORE in globally visible. - This is exactly what happens on x86_64
case-2: CPU-Core wait when Store-Buffer will be flushed, STORE has waited an exclusive-state (E) of cache line and STORE has been done, then CPU-Core loads all required data from cache-line. STORE-LOAD isn't reordered in globally visible. But this is the same as if you used the MFENCE.
Conclusion, you must use MFENCE after STORE in any case:
- It completely solve the problem in the case-1.
- It will not have any effect on the behavior and performance in the case-2. Explicit
MFENCE for empty Store-Buffer will end immediately.
The correct example on C and x86_64 asm:
We force the CPU-Core to act as in the case-2 by using MFENCE, consequently there isn't StoreLoad reordering
Note: xchgb is always has prefix LOCK, so it usually is not written in asm or indicated in brackets.
All other compilers can be selected manually on the links above: PowerPC, ARM, ARM64, MIPS, MIPS64, AVR.
C-code - should use Sequential Consistency for the first STORE and next LOAD:
#ifdef __cplusplus
#include <atomic>
using namespace std;
#else
#include <stdatomic.h>
#endif
// lock - pointer to an aligned int64 variable
// threadNum - integer in the range 0..7
// volatiles here just to show direct r/w of the memory as it was suggested in the comments
int TryLock(volatile uint64_t* lock, uint64_t threadNum)
{
//if (0 != *lock)
if (0 != atomic_load_explicit((atomic_uint_least64_t*)lock, memory_order_acquire))
return 0; // another thread already had the lock
//((volatile uint8_t*)lock)[threadNum] = 1; // take the lock by setting our byte
uint8_t* current_lock = ((uint8_t*)lock) + threadNum;
atomic_store_explicit((atomic_uint_least8_t*)current_lock, (uint8_t)1, memory_order_seq_cst);
//if (1LL << 8*threadNum != *lock)
// You already know that this flag is set and should not have to check it.
if ( 0 != ( (~(1LL << 8*threadNum)) &
atomic_load_explicit((atomic_uint_least64_t*)lock, memory_order_seq_cst) ))
{ // another thread set its byte between our 1st and 2nd check. unset ours
//((volatile uint8_t*)lock)[threadNum] = 0;
atomic_store_explicit((atomic_uint_least8_t*)current_lock, (uint8_t)0, memory_order_release);
return 0;
}
return 1;
}
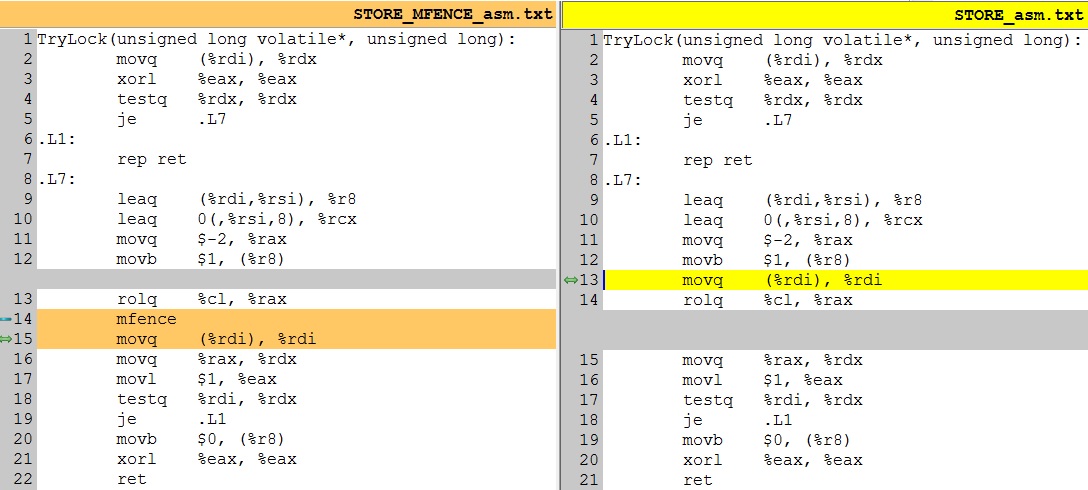
GCC 6.1.0 - x86_64 asm-code - should use MFENCE for the first STORE:
TryLock(unsigned long volatile*, unsigned long):
movq (%rdi), %rdx
xorl %eax, %eax
testq %rdx, %rdx
je .L7
.L1:
rep ret
.L7:
leaq (%rdi,%rsi), %r8
leaq 0(,%rsi,8), %rcx
movq $-2, %rax
movb $1, (%r8)
rolq %cl, %rax
mfence
movq (%rdi), %rdi
movq %rax, %rdx
movl $1, %eax
testq %rdi, %rdx
je .L1
movb $0, (%r8)
xorl %eax, %eax
ret
Full example how it works: http://coliru.stacked-crooked.com/a/65e3002909d8beae
shared_value = 800000
What will happen if you do not use MFENCE - Data-Races
There is a StoreLoad reordering as in the described above case-1 (i.e. if don't use Sequential Consistency for STORE) - asm: https://godbolt.org/g/p3j9fR
I changed the memory barrier for STORE from memory_order_seq_cst to memory_order_release, it removes MFENCE - and now there are data-races - shared_value is not equal to 800000.
![enter image description here]()
mulis an amusing way to compile1LL << 8*threadNum. You could have usedimul eax, edx, 8/ xor-zero /bts. Or better, what gcc does:lea ecx, [0+rdx*8]/mov edx, 1/shl rdx, cl– Morassxor r8, r8 ; shl rdx, 3 ; bts r8, rdx ; xor rax, rax ; lock cmpxchg [rcx], r8 ; setz al ; movzx eax, al ; ret. The movzx is needed if you are returning an int. If you can make your return type a byte, it can be omitted. – Alphonsoxor rax,raxactually assembles to a 3-byte insn with a REX prefix, instead of optimizing toxor eax,eax. You should generally write xor-zeroing with 32bit registers. – Morassif ( ~(1LL << 8*threadNum) & *lock == 0 )3. You should flush store-buffer after this store((volatile INT8*)lock)[threadNum] = 1;MFENCE, because your example requires Sequential Consistency. – Farflung