I converted some audio files to spectrograms and saved them to files using the following code:
import os
from matplotlib import pyplot as plt
import librosa
import librosa.display
import IPython.display as ipd
audio_fpath = "./audios/"
spectrograms_path = "./spectrograms/"
audio_clips = os.listdir(audio_fpath)
def generate_spectrogram(x, sr, save_name):
X = librosa.stft(x)
Xdb = librosa.amplitude_to_db(abs(X))
fig = plt.figure(figsize=(20, 20), dpi=1000, frameon=False)
ax = fig.add_axes([0, 0, 1, 1], frameon=False)
ax.axis('off')
librosa.display.specshow(Xdb, sr=sr, cmap='gray', x_axis='time', y_axis='hz')
plt.savefig(save_name, quality=100, bbox_inches=0, pad_inches=0)
librosa.cache.clear()
for i in audio_clips:
audio_fpath = "./audios/"
spectrograms_path = "./spectrograms/"
audio_length = librosa.get_duration(filename=audio_fpath + i)
j=60
while j < audio_length:
x, sr = librosa.load(audio_fpath + i, offset=j-60, duration=60)
save_name = spectrograms_path + i + str(j) + ".jpg"
generate_spectrogram(x, sr, save_name)
j += 60
if j >= audio_length:
j = audio_length
x, sr = librosa.load(audio_fpath + i, offset=j-60, duration=60)
save_name = spectrograms_path + i + str(j) + ".jpg"
generate_spectrogram(x, sr, save_name)
I wanted to keep the most detail and quality from the audios, so that i could turn them back to audio without too much loss (They are 80MB each).
Is it possible to turn them back to audio files? How can I do it?
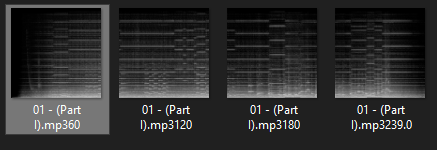
I tried using librosa.feature.inverse.mel_to_audio, but it didn't work, and I don't think it applies.
I now have 1300 spectrogram files and want to train a Generative Adversarial Network with them, so that I can generate new audios, but I don't want to do it if i wont be able to listen to the results later.

amplitude_to_dband the saving to lossy format (jpeg). That being said, unless OP is dealing with some extreme cases, it should not be a big issue. The OP wants to "train a Generative Adversarial Network with them, so that I can generate new audios" and that's not an exact math anyway. Combine that with e.g. tensorflow/magenta and OP is off to a good start. – Dionysus