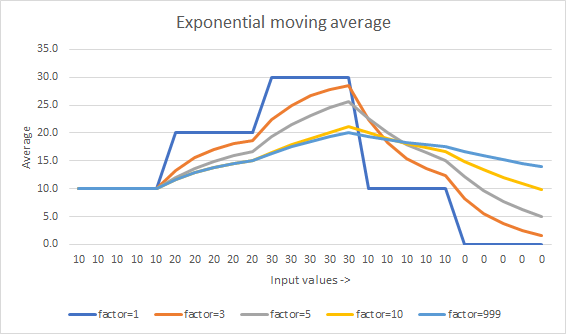
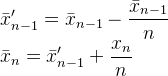Others have mentioned the Welford algorithm. Here is a comparison to Kahan mean algorithm which keeps precision but retains a sum (see demo).
package main
import (
"fmt"
"os"
)
func main() {
values := []float64{
1,
2.1,
3.12,
4.123,
5.1234,
6.1234567890123456789,
7.12345678901234567890123,
}
fmt.Printf("\nKahan mean . . .\n\n")
compareClassicAndKahan(values)
fmt.Printf("\nWelford mean . . .\n\n")
compareClassicAndWelford(values)
}
func compareClassicAndKahan(values []float64) {
sum := float64(0)
runningMean := float64(0)
kahanSum := float64(0)
compensation := float64(0)
for i := 0; i < len(values); i++ {
x := values[i]
count := float64(i + 1)
// Classic mean
sum += x
classicMean := sum / count
// Kahan mean
y := x - compensation
t := kahanSum + y
compensation = (t - kahanSum) - y
kahanSum = t
runningMean = kahanSum / count
checkResult("kahan", count, classicMean, runningMean)
}
}
func compareClassicAndWelford(values []float64) {
sum := float64(0)
runningMean := float64(0)
for i := 0; i < len(values); i++ {
x := values[i]
count := float64(i + 1)
// Classic mean
sum += x
classicMean := sum / count
// Welford mean
runningMean += (x - runningMean) / count
// Print Results
checkResult("welford", count, classicMean, runningMean)
}
}
func checkResult(
name string,
count, classicMean, runningMean float64,
) {
s := fmt.Sprintf(
"%s %f classicMean=%64.64f\n"+
"%s %f runningMean=%64.64f\n\n",
name,
count,
classicMean,
name,
count,
runningMean,
)
if classicMean == runningMean {
fmt.Printf(s)
} else {
fmt.Fprint(os.Stderr, s)
}
}
Kahan means match the classic summation method:
kahan 1.000000 classicMean=1.0000000000000000000000000000000000000000000000000000000000000000
kahan 1.000000 runningMean=1.0000000000000000000000000000000000000000000000000000000000000000
kahan 2.000000 classicMean=1.5500000000000000444089209850062616169452667236328125000000000000
kahan 2.000000 runningMean=1.5500000000000000444089209850062616169452667236328125000000000000
kahan 3.000000 classicMean=2.0733333333333336945258906780509278178215026855468750000000000000
kahan 3.000000 runningMean=2.0733333333333336945258906780509278178215026855468750000000000000
kahan 4.000000 classicMean=2.5857499999999999928945726423989981412887573242187500000000000000
kahan 4.000000 runningMean=2.5857499999999999928945726423989981412887573242187500000000000000
kahan 5.000000 classicMean=3.0932800000000000295585778076201677322387695312500000000000000000
kahan 5.000000 runningMean=3.0932800000000000295585778076201677322387695312500000000000000000
kahan 6.000000 classicMean=3.5983094648353906030990856379503384232521057128906250000000000000
kahan 6.000000 runningMean=3.5983094648353906030990856379503384232521057128906250000000000000
kahan 7.000000 classicMean=4.1019019397178126951075682882219552993774414062500000000000000000
kahan 7.000000 runningMean=4.1019019397178126951075682882219552993774414062500000000000000000
Welford mean has some matches, sortof fixes itself:
welford 1.000000 classicMean=1.0000000000000000000000000000000000000000000000000000000000000000
welford 1.000000 runningMean=1.0000000000000000000000000000000000000000000000000000000000000000
welford 2.000000 classicMean=1.5500000000000000444089209850062616169452667236328125000000000000
welford 2.000000 runningMean=1.5500000000000000444089209850062616169452667236328125000000000000
// welford 3.000000 error see below
welford 4.000000 classicMean=2.5857499999999999928945726423989981412887573242187500000000000000
welford 4.000000 runningMean=2.5857499999999999928945726423989981412887573242187500000000000000
welford 5.000000 classicMean=3.0932800000000000295585778076201677322387695312500000000000000000
welford 5.000000 runningMean=3.0932800000000000295585778076201677322387695312500000000000000000
// welford 6.000000 error see below
welford 7.000000 classicMean=4.1019019397178126951075682882219552993774414062500000000000000000
welford 7.000000 runningMean=4.1019019397178126951075682882219552993774414062500000000000000000
Welford mismatches (errors):
welford 3.000000 classicMean=2.0733333333333336945258906780509278178215026855468750000000000000
welford 3.000000 runningMean=2.0733333333333332504366808279883116483688354492187500000000000000
welford 6.000000 classicMean=3.5983094648353906030990856379503384232521057128906250000000000000
welford 6.000000 runningMean=3.5983094648353910471882954880129545927047729492187500000000000000