What could be an optimal solution to limit the no. of threads (<256 as
the range of n is 2 to max of long)?
First, you should consider the hardware where the code will be executed (e.g., the number of cores) and the type of algorithm that you are parallelizing, namely is it CPU-bound?, memory-bound?, IO-bound, and so on.
Your code is CPU-bound, therefore, from a performance point of view, typically does not payoff having more threads running than the number of available cores in the system. As is always the case profile as much as you can.
Second, you need to distribute work among threads in a way that justifies the parallelism, in your case:
for (ref.x = 2; ref.x < (n + 2) / 2; ref.x++) {
if (t.activeCount() < 256) {
new Thread(t, () -> {
for (ref.y = 2; ref.y < (n + 2) / 2; ref.y++) {
long z = lcm(ref.x, ref.y) + gcd(ref.x, ref.y);
if (z == n) {
ref.ret = new long[]{ref.x, ref.y};
t.interrupt();
break;
}
}
}, "Thread_" + ref.x).start();
if (ref.ret != null) {
return ref.ret;
}
} else {
ref.x--;
}
}//return new long[]{1, n - 2};
which you kind of did, however IMO in a convoluted way; much easier IMO is to parallelize the loop explicitly, i.e., splitting its iterations among threads, and remove all the ThreadGroup related logic.
Third, lookout for race-conditions such as :
var ref = new Object() {
long x;
long y;
long[] ret = null;
};
this object is shared among threads, and updated by them, consequently leading to race-conditions. As we are about to see you do not actually need such a shared object anyway.
So let us do this step by step:
First, find out the number of threads that you should execute the code with i.e., the same number of threads as cores:
int cores = Runtime.getRuntime().availableProcessors();
Define the parallel work (this a possible example of a loop distribution):
public void run() {
for (int x = 2; && x < (n + 2) / 2; x ++) {
for (int y = 2 + threadID; y < (n + 2) / 2; y += total_threads) {
long z = lcm(x, y) + gcd(x, y);
if (z == n) {
// do something
}
}
}
}
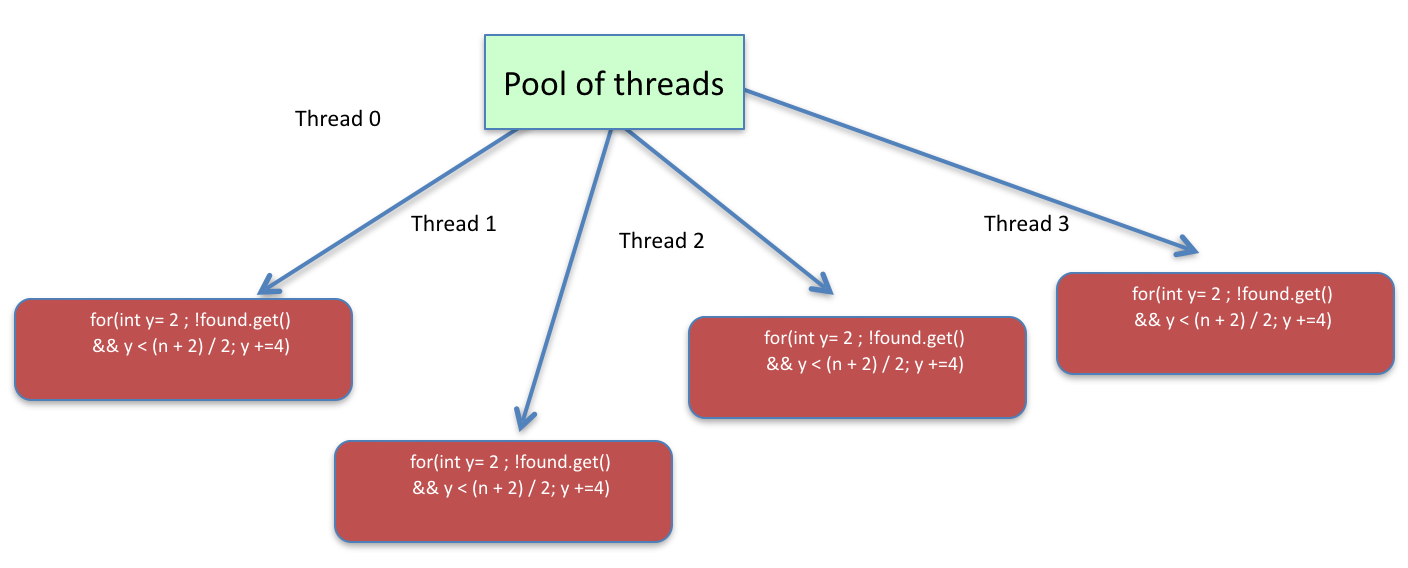
in the code below, we split the work to be done in parallel in a round-robin fashion among threads as showcased in the image below:
![enter image description here]()
I want to stop the code execution as soon as the first pair is found.
There are several ways of achieving this. I will provide the simplest IMO, albeit not the most sophisticated. You can use a variable to signal to the threads when the result was already found, for instance:
final AtomicBoolean found;
each thread will share the same AtomicBoolean variable so that the change performed in one of them are also visible to the others:
@Override
public void run() {
for (int x = 2 ; !found.get() && x < (n + 2) / 2; x ++) {
for (int y = 2 + threadID; y < (n + 2) / 2; y += total_threads) {
long z = lcm(x, y) + gcd(x, y);
if (z == n) {
synchronized (found) {
if(!found.get()) {
rest[0] = x;
rest[1] = y;
found.set(true);
}
return;
}
}
}
}
}
Since you were asking for a code snippet example here is a simple non-bulletproof (and not properly tested) running coding example:
class ThreadWork implements Runnable{
final long[] rest;
final AtomicBoolean found;
final int threadID;
final int total_threads;
final long n;
ThreadWork(long[] rest, AtomicBoolean found, int threadID, int total_threads, long n) {
this.rest = rest;
this.found = found;
this.threadID = threadID;
this.total_threads = total_threads;
this.n = n;
}
static long gcd(long a, long b) {
return (a == 0) ? b : gcd(b % a, a);
}
static long lcm(long a, long b, long gcd) {
return (a / gcd) * b;
}
@Override
public void run() {
for (int x = 2; !found.get() && x < (n + 2) / 2; x ++) {
for (int y = 2 + threadID; !found.get() && y < (n + 2) / 2; y += total_threads) {
long result = gcd(x, y);
long z = lcm(x, y, result) + result;
if (z == n) {
synchronized (found) {
if(!found.get()) {
rest[0] = x;
rest[1] = y;
found.set(true);
}
return;
}
}
}
}
}
}
class PerfectPartition {
public static void main(String[] args) throws InterruptedException {
Scanner sc = new Scanner(System.in);
final long n = sc.nextLong();
final int total_threads = Runtime.getRuntime().availableProcessors();
long[] rest = new long[2];
AtomicBoolean found = new AtomicBoolean();
double startTime = System.nanoTime();
Thread[] threads = new Thread[total_threads];
for(int i = 0; i < total_threads; i++){
ThreadWork task = new ThreadWork(rest, found, i, total_threads, n);
threads[i] = new Thread(task);
threads[i].start();
}
for(int i = 0; i < total_threads; i++){
threads[i].join();
}
double estimatedTime = System.nanoTime() - startTime;
System.out.println(rest[0] + " " + rest[1]);
double elapsedTimeInSecond = estimatedTime / 1_000_000_000;
System.out.println(elapsedTimeInSecond + " seconds");
}
}
OUTPUT:
4 -> 2 2
8 -> 4 4
Used this code as inspiration to come up with your own solution that best fits your requirements. After you fully understand those basics, try to improve the approach with more sophisticated Java features such as Executors, Futures, CountDownLatch.
NEW UPDATE: Sequential Optimization
Looking at the gcd method:
static long gcd(long a, long b) {
return (a == 0)? b : gcd(b % a, a);
}
and the lcm method:
static long lcm(long a, long b) {
return (a / gcd(a, b)) * b;
}
and how they are being used:
long z = lcm(ref.x, ref.y) + gcd(ref.x, ref.y);
you can optimize your sequential code by not calling again gcd(a, b) in the lcm method. So change lcm method to:
static long lcm(long a, long b, long gcd) {
return (a / gcd) * b;
}
and
long z = lcm(ref.x, ref.y) + gcd(ref.x, ref.y);
to
long result = gcd(ref.x, ref.y)
long z = lcm(ref.x, ref.y, gcd) + gcd;
The code that I have provided in this answer already reflects those changes.
mainthread wait and the successful thread notify themainto resume? – Ironist