I have a dataframe, where the left column is the left - most location of an object, and the right column is the right most location. I need to group the objects if they overlap, or they overlap objects that overlap (recursively).
So, for example, if this is my dataframe:
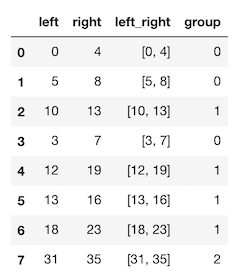
left right
0 0 4
1 5 8
2 10 13
3 3 7
4 12 19
5 18 23
6 31 35
so lines 0 and 3 overlap - thus they should be on the same group, and also line 1 is overlapping line 3 - thus it joins the group.
So, for this example the output should be something like that:
left right group
0 0 4 0
1 5 8 0
2 10 13 1
3 3 7 0
4 12 19 1
5 18 23 1
6 31 35 2
I thought of various directions, but didn't figure it out (without an ugly for).
Any help will be appreciated!