Updates
I've long since removed the power-of-two suggestion from the docs because 1) with the current dict grow rate, the effect is minimal and 2) because the optimal maxsize should been 2**n * 2//3 + 1.
Measuring the effect
Here's a timing tool demonstrates the impact of different maxsize values:
from time import perf_counter
from functools import lru_cache
from itertools import cycle, islice
def cache_performance(maxsize, times=10**8):
"Performance of *times* misses for a given *maxsize*."
func = lru_cache(maxsize)(type)
data = (object() for i in range(n+1)) # n+1 distinct objects
iterator = islice(cycle(data), times)
start = perf_counter()
for x in iterator:
func(x)
return perf_counter() - start, func.cache_info()
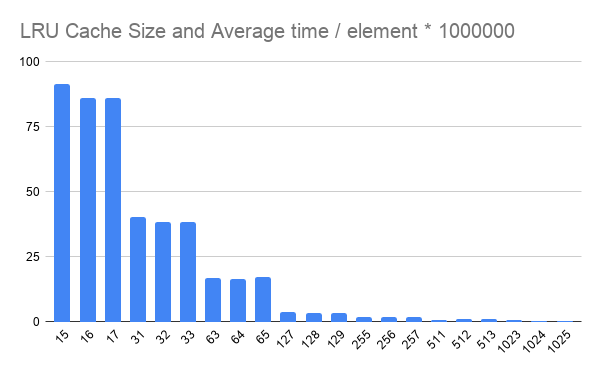
Running it values near the transition optimum shows a small 6% degradation just below the optimum maxsize. This is so small that we don't notice anymore. But when the dict's internal growth rate was only 2x, the degradation was large and devastating:
>>> for n in [699_050, 699_051, 699_052, 699_053]:
... print(*cache_performance(n), sep='\t')
...
15.266257792012766 CacheInfo(hits=0, misses=100000000, maxsize=699050, currsize=699050)
15.06655020796461 CacheInfo(hits=0, misses=100000000, maxsize=699051, currsize=699051)
14.196706458984409 CacheInfo(hits=0, misses=100000000, maxsize=699052, currsize=699052)
14.19534025003668 CacheInfo(hits=0, misses=100000000, maxsize=699053, currsize=699053)
Why size effect arises
The lru_cache() code exercises its underlying dictionary in an atypical way. While maintaining total constant size, cache misses delete the oldest item and insert a new item.
The size suggestion is an artifact of how this delete-and-insert pattern interacts with the underlying dictionary implementation.
How dictionaries work
- Table sizes are a power of two.
- Deleted keys are replaced with dummy entries.
- New keys can sometimes reuse the dummy slot, sometimes not.
- Repeated delete-and-inserts with different keys will fill-up the table with dummy entries.
- An O(N) resize operation runs when the table is two-thirds full.
- Since the number of active entries remains constant, a resize operation doesn't actually change the table size.
- The only effect of the resize is to clear the accumulated dummy entries.
Performance implications
A dict with 2**n * 2 // 3 + 1 entries has the most available space for dummy entries, so the O(n) resizes occur less often.
Also, sparse dictionaries have fewer hash collisions than mostly full dictionaries. Collisions degrade dictionary performance.
When it matters
The lru_cache() only updates the dictionary when there is a cache miss. Also, when there is a miss, the wrapped function is called. So, the effect of resizes would only matter if there are high proportion of misses and if the wrapped function is very cheap.
Far more important than setting the maxsize just above a resize transition point is using the largest reasonable maxsize. Bigger caches have more cache hits — that's where the big wins come from.
Simulation
Once an lru_cache() is full and the first resize has occurred, the dictionary settles into a steady state and will never get larger. Here, we simulate what happens next as new dummy entries are added and periodic resizes clear them away.
table_size = 2 ** 7
resize_point = table_size * 2 // 3
def simulate_lru_cache(lru_maxsize, misses=1_000_000):
'Track resize workload as cache misses occur.'
filled = lru_maxsize
resizes = 0
work = 0
for i in range(misses):
filled += 1
if filled >= resize_point:
resizes += 1
work += lru_maxsize # copy active entries
filled = lru_maxsize # dummies not copied
work_per_miss = work / misses
print(lru_maxsize, '→', resizes, work_per_miss)
Here is an excerpt of the output:
>>> for maxsize in range(43, 85):
... simulate_lru_cache(maxsize, sep='\t')
...
43 → 23809 1.023787
44 → 24390 1.07316
45 → 25000 1.125
46 → 25641 1.179486
47 → 26315 1.236805
48 → 27027 1.297296
49 → 27777 1.361073
50 → 28571 1.42855
51 → 29411 1.499961
52 → 30303 1.575756
53 → 31250 1.65625
54 → 32258 1.741932
55 → 33333 1.833315
56 → 34482 1.930992
57 → 35714 2.035698
58 → 37037 2.148146
59 → 38461 2.269199
60 → 40000 2.4
61 → 41666 2.541626
62 → 43478 2.695636
63 → 45454 2.863602
64 → 47619 3.047616
65 → 50000 3.25
66 → 52631 3.473646
67 → 55555 3.722185
68 → 58823 3.999964
69 → 62500 4.3125
70 → 66666 4.66662
71 → 71428 5.071388
72 → 76923 5.538456
73 → 83333 6.083309
74 → 90909 6.727266
75 → 100000 7.5
76 → 111111 8.444436
77 → 125000 9.625
78 → 142857 11.142846
79 → 166666 13.166614
80 → 200000 16.0
81 → 250000 20.25
82 → 333333 27.333306
83 → 500000 41.5
84 → 1000000 84.0
What this shows is that the cache does significantly less work when maxsize is as far away as possible from the resize_point.
Finding the transition points
The dictionary size transition points are directly observable:
from sys import getsizeof
d = {}
seen = set()
for i in range(1_000_000):
s = getsizeof(d)
d[i] = None
if s not in seen:
seen.add(s)
print(len(d))
On Python 3.13, this reveals the following transition points:
1
2
7
12
23
44
87
172
343
684
1367
2732
5463
10924
21847
43692
87383
174764
349527
699052
History
The effect was minimal in Python3.2, when dictionaries grew by 4 x active_entries when resizing.
The effect became catastrophic when the growth rate was lowered to 2 x active entries.
Later a compromise was reached, setting the growth rate to 3 x used. That significantly mitigated the issue by giving us a larger steady state size by default.
A power-of-two maxsize is still the optimum setting, giving the least work for a given steady state dictionary size, but it no longer matters as much as it did in Python3.2.
Hope this helps clear up your understanding. :-)