I wrote a unit-test in order to safe a model after noticing that I am not able to do so (anymore) during training.
@pytest.mark.usefixtures("maybe_run_functions_eagerly")
def test_save_model(speech_model: Tuple[TransducerBase, SpeechFeaturesConfig]):
model, speech_features_config = speech_model
speech_features_config: SpeechFeaturesConfig
channels = 3 if speech_features_config.add_delta_deltas else 1
num_mel_bins = speech_features_config.num_mel_bins
enc_inputs = np.random.rand(1, 50, num_mel_bins, channels)
dec_inputs = np.expand_dims(np.random.randint(0, 25, size=10), axis=1)
inputs = enc_inputs, dec_inputs
model(inputs)
# Throws KeyError:
# graph = tf.compat.v1.get_default_graph()
# tensor = graph.get_tensor_by_name("77040:0")
directory = tempfile.mkdtemp(prefix=f"{model.__class__.__name__}_")
try:
model.save(directory)
finally:
shutil.rmtree(directory)
Trying to save the model will always throw the following error:
E AssertionError: Tried to export a function which references untracked resource Tensor("77040:0", shape=(), dtype=resource). TensorFlow objects (e.g. tf.Variable) captured by functions must be tracked by assigning them to an attribute of a tracked object or assigned to an attribute of the main object directly.
E
E Trackable Python objects referring to this tensor (from gc.get_referrers, limited to two hops):
E <tf.Variable 'transformer_transducer/transducer_encoder/inputs_embedding/convolution_stack/conv2d/kernel:0' shape=(3, 3, 3, 32) dtype=float32>
Note: As you can see in the code above, but I am not able to retrieve this tensor with
tf.compat.v1.get_default_graph().get_tensor_by_name("77040:0").I tried the following too, but the result is always empty:
model(batch) # Build the model tensor_name = "77040" var_names = [var.name for var in model.trainable_weights] weights = list(filter(lambda var: tensor_name in var, var_names)) var_names = [var.name for var in model.trainable_variables] variables = list(filter(lambda var: tensor_name in var, var_names)) print(weights) print(variables)
The problem is that I do not understand why I am getting this because the affected layer is tracked by Keras as you can see in the screenshot below. I took it during a debug-session in the call() function.
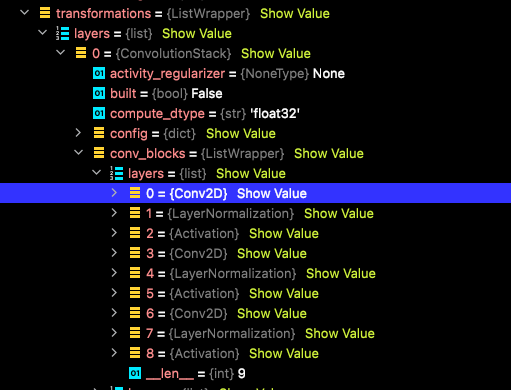
I have no explanation for this and I am running out of ideas what the issue might be here.
The transformations list in the screenshot is a property of and getting constructed by a layer InputsEmbedding like so:
class InputsEmbedding(layers.Layer, TimeReduction):
def __init__(self, config: InputsEmbeddingConfig, **kwargs):
super().__init__(**kwargs)
if config.transformations is None or not len(config.transformations):
raise RuntimeError("No transformations provided.")
self.config = config
self.transformations = list()
for transformation in self.config.transformations:
layer_name, layer_params = list(transformation.items())[0]
layer = _get_layer(layer_name, layer_params)
self.transformations.append(layer)
self.init_time_reduction_layer()
def get_config(self):
return self.config.dict()
def _get_layer(name: str, params: dict) -> layers.Layer:
if name == "conv2d_stack":
return ConvolutionStack(**params)
elif name == "stack_frames":
return StackFrames(**params)
else:
raise RuntimeError(f"Unsupported or unknown time-reduction layer {name}")
In order to verify that the problem is not the InputsEmbedding, I created a unit-text for saving a model that is using just this particular layer.
@pytest.mark.usefixtures("maybe_run_functions_eagerly")
def test_inputs_embedding_save_model():
convolutions = [
"filters=2, kernel_size=(3, 3), strides=(2, 1)",
"filters=4, kernel_size=(3, 3), strides=(2, 1)",
"filters=8, kernel_size=(3, 4), strides=(1, 1)",
]
config = InputsEmbeddingConfig()
config.transformations = [dict(conv2d_stack=dict(convolutions=convolutions)), dict(stack_frames=dict(n=2))]
num_features = 8
num_channels = 3
inputs = layers.Input(shape=(None, num_features, num_channels))
x = inputs
x, _ = InputsEmbedding(config)(x)
model = keras.Model(inputs=inputs, outputs=x)
model.build(input_shape=(1, 20, num_features, num_channels))
directory = tempfile.mkdtemp(prefix=f"{model.__class__.__name__}_")
try:
model.save(directory)
finally:
shutil.rmtree(directory)
Here I am able to save this layer without any issues:

ConvolutionStack
As it seems to be relevant, here is the (rather ugly) implementation of ConvolutionStack:
from typing import List
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.python.keras.layers import convolutional
from speech.lab.layers import InputsRequirements
from speech.lab.models import conv_util, models_util
class ConvolutionStack(layers.Layer):
def __init__(
self,
convolutions: List[str],
kernel_regularizer: dict = None,
bias_regularizer: dict = None,
**kwargs
):
super().__init__(**kwargs)
self.config = dict(
convolutions=convolutions,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer
)
self.conv_stack_config = [eval(f"dict({convolution})") for convolution in convolutions]
self.conv_blocks = list()
if kernel_regularizer is not None:
kernel_regularizer = models_util.maybe_to_regularizer(kernel_regularizer)
if bias_regularizer is not None:
bias_regularizer = models_util.maybe_to_regularizer(bias_regularizer)
for block_config in self.conv_stack_config:
block = _new_convolution_block(
**block_config,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer,
)
self.conv_blocks.append(block)
self.drop_dim2 = layers.Lambda(tf.squeeze, arguments=dict(axis=-2))
self.expand_last = layers.Lambda(tf.expand_dims, arguments=dict(axis=-1))
@property
def inputs_requirements(self) -> InputsRequirements:
requirements, frame_look_back = conv_util.get_conv2d_stack_requirements(self.conv_stack_config)
first = requirements[0]
t_min, f_size = first["min_size"]
t_grow, f_grow = first["grow_size"]
return InputsRequirements(
frame_look_back=frame_look_back,
t_min=t_min,
t_grow=t_grow,
f_min=f_size,
f_grow=f_grow,
)
def call(self, inputs, training=None, mask=None, **kwargs):
"""
:param inputs:
Tensor taking the form [batch, time, freq, channel]
:param training:
:param mask:
:param kwargs:
:return:
Tensor taking the form [batch, time, freq, 1]
"""
if training:
t_min = self.inputs_requirements.t_min
t_grow = self.inputs_requirements.t_grow
pad = conv_util.get_padding_for_loss(tf.shape(inputs)[1], t_min=t_min, t_grow=t_grow)
inputs = tf.pad(inputs, ((0, 0), (0, pad), (0, 0), (0, 0)))
if mask is not None:
mask = tf.pad(mask, ((0, 0), (0, pad)))
f_min = self.inputs_requirements.f_min
f_grow = self.inputs_requirements.f_grow
assert (inputs.shape[2] - f_min) % f_grow == 0, (
f'Inputs dimension "freq" ' f"expected to be {f_min} + n * {f_grow} but got {inputs.shape[2]} instead."
)
x = inputs
for block in self.conv_blocks:
for layer in block:
if mask is not None and isinstance(layer, convolutional.Conv):
st, _ = layer.strides
kt = tf.maximum(layer.kernel_size[0] - 1, 1)
mask = mask[:, :-kt][:, ::st]
mask = tf.pad(mask, ((0, 0), (0, tf.maximum(2 - layer.kernel_size[0], 0))))
x = layer(x, training=training)
return self.expand_last(self.drop_dim2(x)), mask
def get_config(self):
return self.config
def _new_convolution_block(
filters: int,
kernel_size: tuple,
strides: tuple,
use_bias: bool = False,
use_norm: bool = True,
kernel_regularizer=None,
bias_regularizer=None,
activation=None,
):
assert strides[0] % 2 == 0 or strides[0] == 1, "Strides on the time axis must be divisible by 2 or be exactly 1."
if activation is not None:
activation_layer = layers.Activation(activation)
else:
activation_layer = layers.Lambda(lambda x: x)
if use_norm:
norm_layer = layers.LayerNormalization()
else:
norm_layer = layers.Lambda(lambda x: x)
return (
layers.Conv2D(
filters=filters,
kernel_size=kernel_size,
strides=strides,
use_bias=use_bias,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer,
),
norm_layer,
activation_layer,
)