I am modelling a graph for an application that I am building currently, where I have n Users connected to n Users, I also have n Posts which can be liked by n Users. So the structure would look something like this, for a given user,
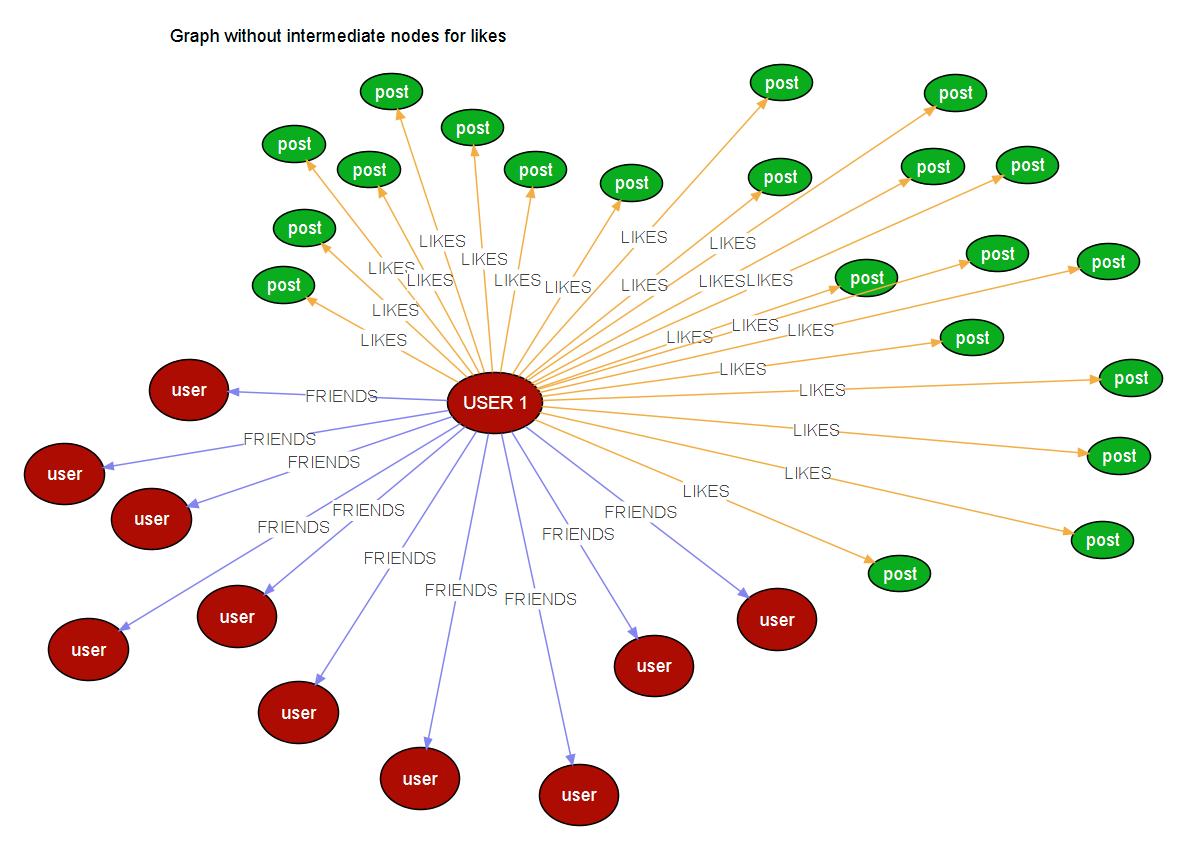
if a user likes hundred Post nodes, It would generate 100 edges (realtionships) to the node, when the post is n, the edges will also be n. so one user will be connected to n Users and n posts and n future node types.
So of using an intermediate node thus reducing the edges to the given node, which would look something like this,
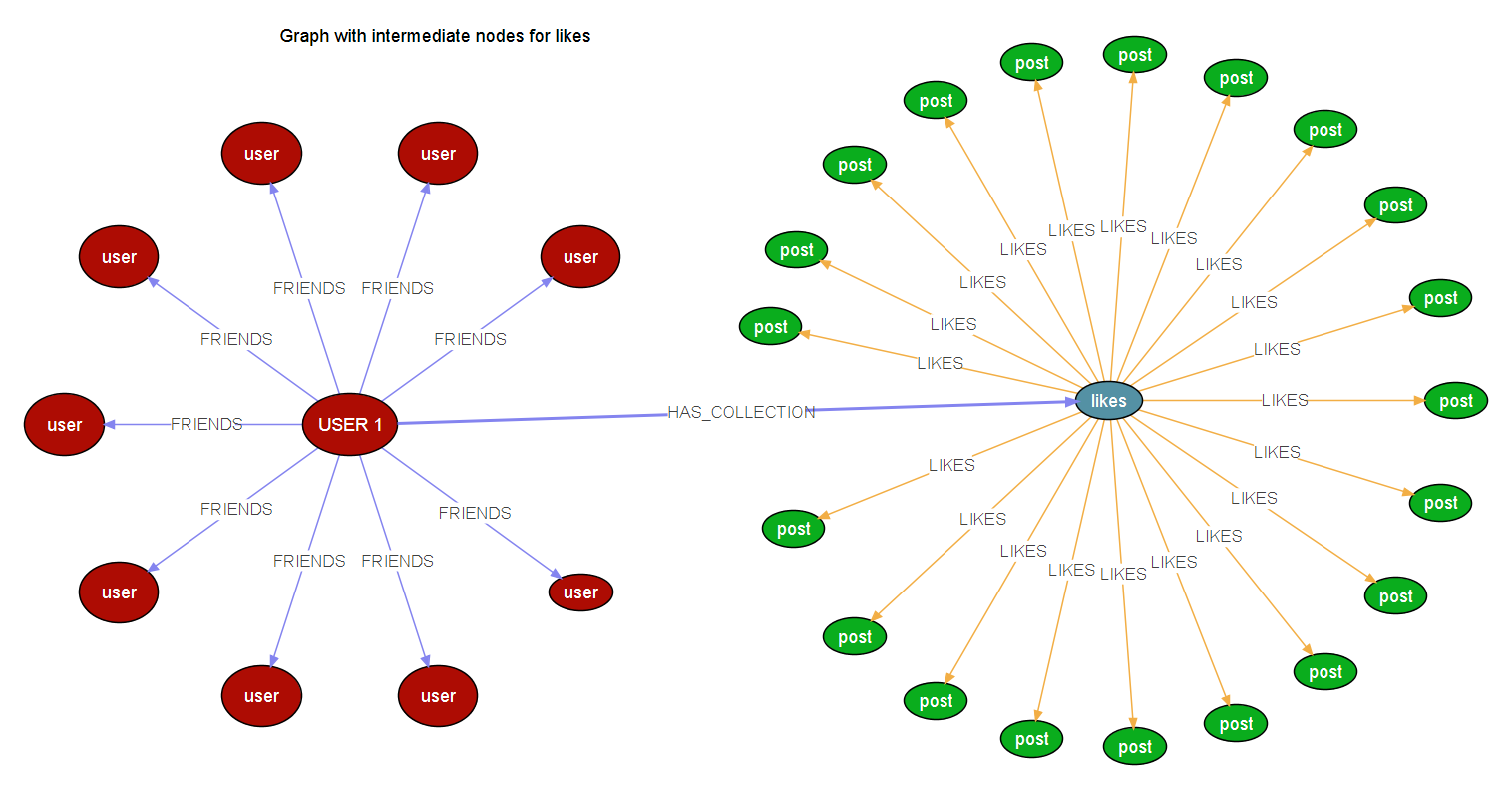
Where the users has an intermediate node named Collection, which will be connected to likes, since this is a property graph, I can add a property to the intermediate node and make it behave like the connections are from the user (something like, Likes.username = User.username)
This will similar to this question (Graph database modelling: Should i use a collection node to avoid to many rel on a node)
my thought is
This way of intermediate connecting nodes can isolate junk from the primary node, thus can speed up custom algorithms.
My questions,
- What is the best solution to this that scales?
- Why should I consider this solution over the other?
