Explanation
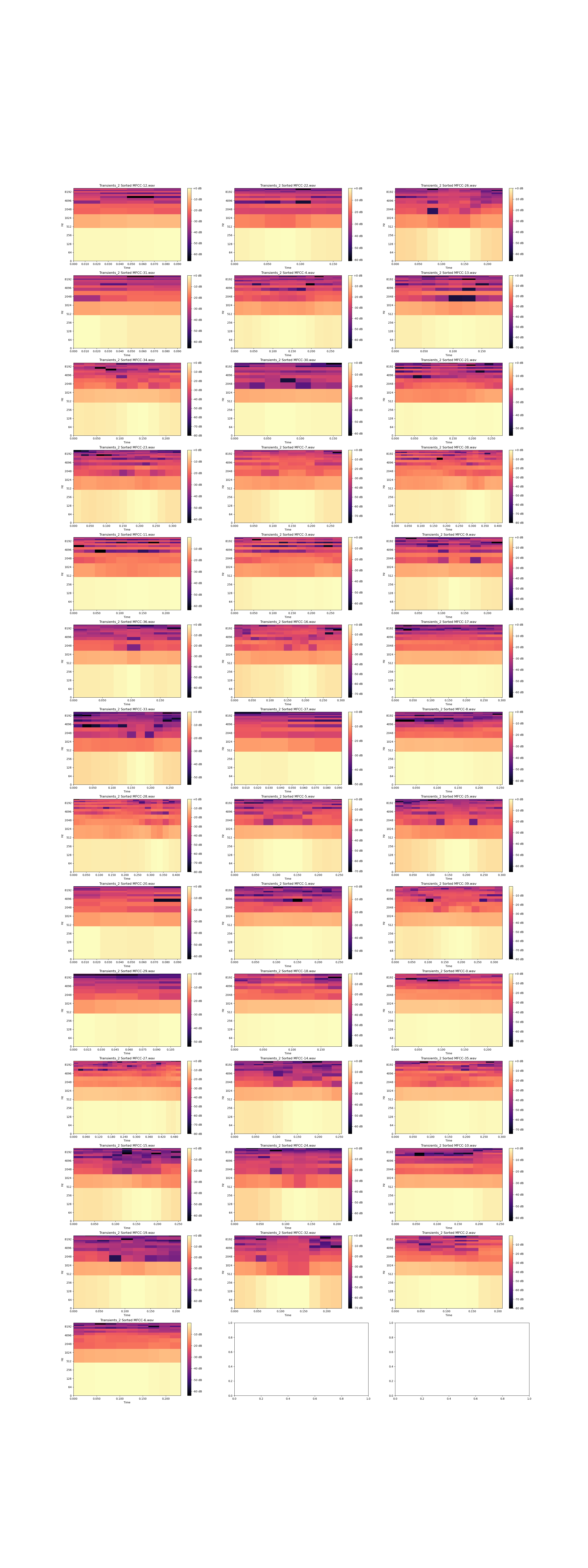
I want to be able to sort a collection of sounds in a list based on the timbre(tone) of the sound. Here is a toy example where I manually sorted the spectrograms for 12 sound files that I created and uploaded to this repo. I know that these are sorted correctly because the sound produced for each file, is exactly the same as the sound in the file before it, but with one effect or filter added to it.
For example, a correct sorting of sounds x, y and z where
- sounds x and y are the same, but y has a distortion effect
- sounds y and z are the same, but z filters out high frequencies
- sounds x and z are the same, but z has a distortion effect, and z filters out high frequencies
Would be x, y, z
Just by looking at the spectrograms, I can see some visual indicators that hint at how the sounds should be sorted, but I would like to automate the sorting process by having a computer recognize such indicators.
The sound files for the sounds in the image above
- are all the same length
- all the same note/pitch
- all start at exactly the same time.
- all the same amplitude (level of loudness)
I would like my sorting to work even if all of these conditions are not true(but I'll accept the best answer even if it doesn't solve this)
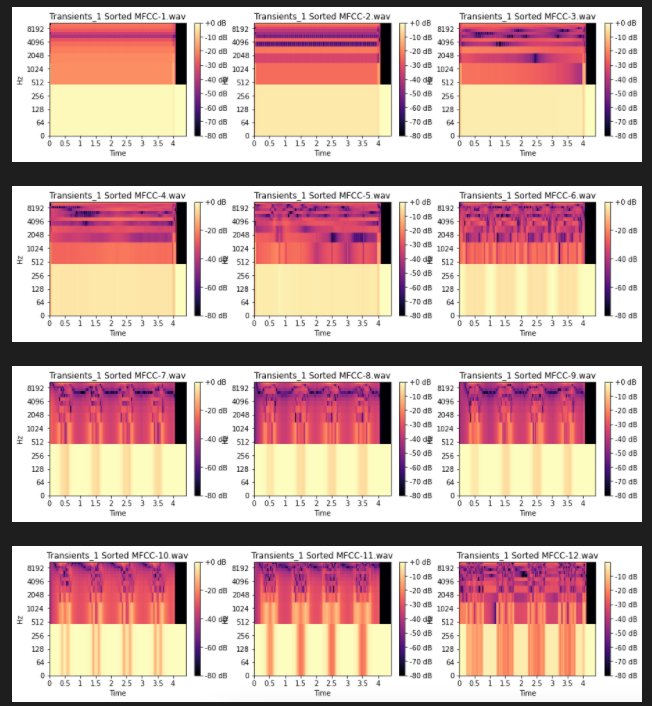
For example, in the image below
- the start of MFCC_8 is shifted in comparison to MFCC_8 in the first image
- MFCC_9 is identical to MFCC_9 in the first image, but is duplicated (so it is twice as long)
If MFCC_8 and MFCC_9 in the first image were replaced with MFCC_8 and MFCC_9 in the image below, I would like the sorting of sounds to remain the exact same.

For my real program, I intend to break up an mp3 file by sound changes like this
My program so far
Here is the program which produces the first image in this post. I need the code in the function sort_sound_files to be replaced with some code that actually sorts the sound files based on timbre. The part which needs to be done is near the bottom and the sound files on on this repo. I also have this code in a jupyter notebook, which also includes a second example that is more similar to what I actually want this program to do
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
import math
from os import path
from typing import List
class Spec:
name: str = ''
sr: int = 44100
class MFCC(Spec):
mfcc: np.ndarray # Mel-frequency cepstral coefficient
delta_mfcc: np.ndarray # delta Mel-frequency cepstral coefficient
delta2_mfcc: np.ndarray # delta2 Mel-frequency cepstral coefficient
n_mfcc: int = 13
def __init__(self, soundFile: str):
self.name = path.basename(soundFile)
y, sr = librosa.load(soundFile, sr=self.sr)
self.mfcc = librosa.feature.mfcc(y, n_mfcc=self.n_mfcc, sr=sr)
self.delta_mfcc = librosa.feature.delta(self.mfcc, mode="nearest")
self.delta2_mfcc = librosa.feature.delta(self.mfcc, mode="nearest", order=2)
def get_mfccs(sound_files: List[str]) -> List[MFCC]:
'''
:param sound_files: Each item is a path to a sound file (wav, mp3, ...)
'''
mfccs = [MFCC(sound_file) for sound_file in sound_files]
return mfccs
def draw_specs(specList: List[Spec], attribute: str, title: str):
'''
Takes a list of same type audio features, and draws a spectrogram for each one
'''
def draw_spec(spec: Spec, attribute: str, fig: plt.Figure, ax: plt.Axes):
img = librosa.display.specshow(
librosa.amplitude_to_db(getattr(spec, attribute), ref=np.max),
y_axis='log',
x_axis='time',
ax=ax
)
ax.set_title(title + str(spec.name))
fig.colorbar(img, ax=ax, format="%+2.0f dB")
specLen = len(specList)
fig, axs = plt.subplots(math.ceil(specLen/3), 3, figsize=(30, specLen * 2))
for spec in range(0, len(specList), 3):
draw_spec(specList[spec], attribute, fig, axs.flat[spec])
if (spec+1 < len(specList)):
draw_spec(specList[spec+1], attribute, fig, axs.flat[spec+1])
if (spec+2 < len(specList)):
draw_spec(specList[spec+2], attribute, fig, axs.flat[spec+2])
sound_files_1 = [
'../assets/transients_1/4.wav',
'../assets/transients_1/6.wav',
'../assets/transients_1/1.wav',
'../assets/transients_1/11.wav',
'../assets/transients_1/13.wav',
'../assets/transients_1/9.wav',
'../assets/transients_1/3.wav',
'../assets/transients_1/7.wav',
'../assets/transients_1/12.wav',
'../assets/transients_1/2.wav',
'../assets/transients_1/5.wav',
'../assets/transients_1/10.wav',
'../assets/transients_1/8.wav'
]
mfccs_1 = get_mfccs(sound_files_1)
##################################################################
def sort_sound_files(sound_files: List[str]):
# TODO: Complete this function. The soundfiles must be sorted based on the content in the file, do not use the name of the file
# This is the correct order that the sounds should be sorted in
return [f"../assets/transients_1/{num}.wav" for num in range(1, 14)] # TODO: remove(or comment) once method is completed
##################################################################
sorted_sound_files_1 = sort_sound_files(sound_files_1)
mfccs_1 = get_mfccs(sorted_sound_files_1)
draw_specs(mfccs_1, 'mfcc', "Transients_1 Sorted MFCC-")
plt.savefig('sorted_sound_spectrograms.png')
EDIT
I didn't realize this until later, but another pretty important thing is that there's going to be lot's of properties that are oscillating. The difference between sound 5 and sound 6 from the first set for example is that sound 6 is sound 5 but with oscillation on the volume (an LFO), this type of oscillation can be placed on a frequency filter, an effect (like distortion) or even pitch. I realize this makes the problem a lot trickier and it's outside the scope of what I asked. Do you have any advice? I could even use several different sorts, and only look at one property at one time.