I am using SSIS in VS 2013.
I need to get a list of IDs from 1 database, and with that list of IDs, I want to query another database, ie SELECT ... from MySecondDB WHERE ID IN ({list of IDs from MyFirstDB}).
Query a database based on result of query from another database
Are the dbs on the same server? –
Younger
No, they are on 2 different servers. –
Bohannon
Google sp_addlinkedserver –
Pigweed
There is 3 Methods to achieve this:
1st method - Using Lookup Transformation
First you have to add a Lookup Transformation like @TheEsisia answered but there are more requirements:
In the Lookup you Have to write the query that contains the ID list (ex:
SELECT ID From MyFirstDB WHERE ...)At least you have to select one column from the lookup table
- These will not filter rows , but this will add values from the second table
To filter rows WHERE ID IN ({list of IDs from MyFirstDB}) you have to do some work in the look up error output Error case there are 2 ways:

- set Error handling to
Ignore Rowso the added columns (from lookup) values will be null , so you have to add aConditional splitthat filter rows having values equal NULL.
Assuming that you have chosen col1 as lookup column so you have to use a similar expression
ISNULL([col1]) == False
- Or you can set Error handling to
Redirect Row, so all rows will be sent to the error output row, which may not be used, so data will be filtered
The disadvantage of this method is that all data is loaded and filtered during execution.
Also if working on network filtering is done on local machine (2nd method on server) after all data is loaded is memory.
2nd method - Using Script Task
To avoid loading all data, you can do a workaround, You can achieve this using a Script Task: (answer writen in VB.NET)
Assuming that the connection manager name is TestAdo and "Select [ID] FROM dbo.MyTable" is the query to get the list of id's , and User::MyVariableList is the variable you want to store the list of id's
Note: This code will read the connection from the connection manager
Public Sub Main()
Dim lst As New Collections.Generic.List(Of String)
Dim myADONETConnection As SqlClient.SqlConnection
myADONETConnection = _
DirectCast(Dts.Connections("TestAdo").AcquireConnection(Dts.Transaction), _
SqlClient.SqlConnection)
If myADONETConnection.State = ConnectionState.Closed Then
myADONETConnection.Open()
End If
Dim myADONETCommand As New SqlClient.SqlCommand("Select [ID] FROM dbo.MyTable", myADONETConnection)
Dim dr As SqlClient.SqlDataReader
dr = myADONETCommand.ExecuteReader
While dr.Read
lst.Add(dr(0).ToString)
End While
Dts.Variables.Item("User::MyVariableList").Value = "SELECT ... FROM ... WHERE ID IN(" & String.Join(",", lst) & ")"
Dts.TaskResult = ScriptResults.Success
End Sub
And the User::MyVariableList should be used as source (Sql command in a variable)
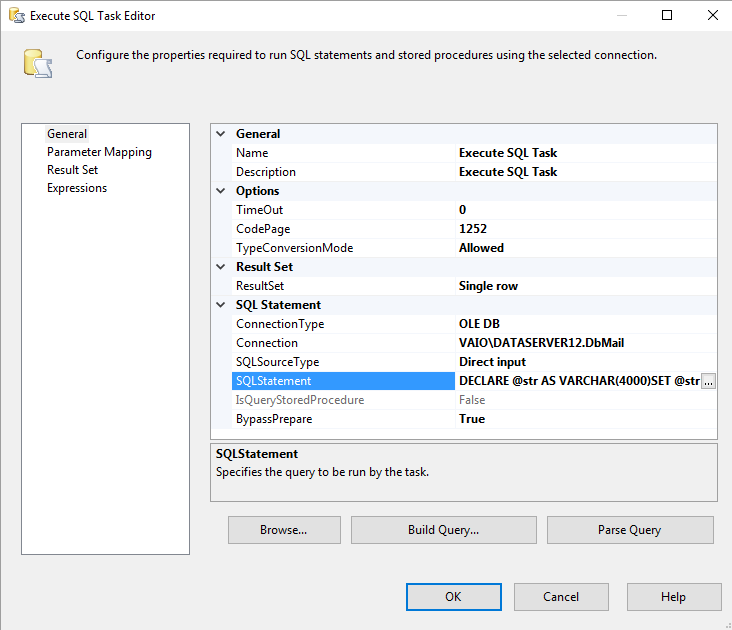
3rd method - Using Execute Sql Task
Similar to the second method but this will build the IN clause using an Execute SQL Task then using the whole query as OLEDB Source,
- Just add an Execute SQL Task before the DataFlow Task
- Set
ResultSetproperty tosingle - Select
User::MyVariableListas Result Set Use the following SQL command
DECLARE @str AS VARCHAR(4000) SET @str = '' SELECT @str = @str + CAST([ID] AS VARCHAR(255)) + ',' FROM dbo.MyTable SET @str = 'SELECT * FROM MySecondDB WHERE ID IN (' + SUBSTRING(@str,1,LEN(@str) - 1) + ')' SELECT @str

If the column has string data type you should add quotation before and after values as below:
SELECT @str = @str + '''' + CAST([ID] AS VARCHAR(255)) + ''','
FROM dbo.MyTable
Make sure that you have set the DataFlow Task Delay Validation property to True
Nice explanation ! –
Geier
Is option 3 applicable where you may have over 100 thousand ID's? It appears to be selecting an individual ID in the
where ID in (select... statement –
Theroid @Theroid this approach is not preferred when dealing with a high number of IDs –
Schmaltzy
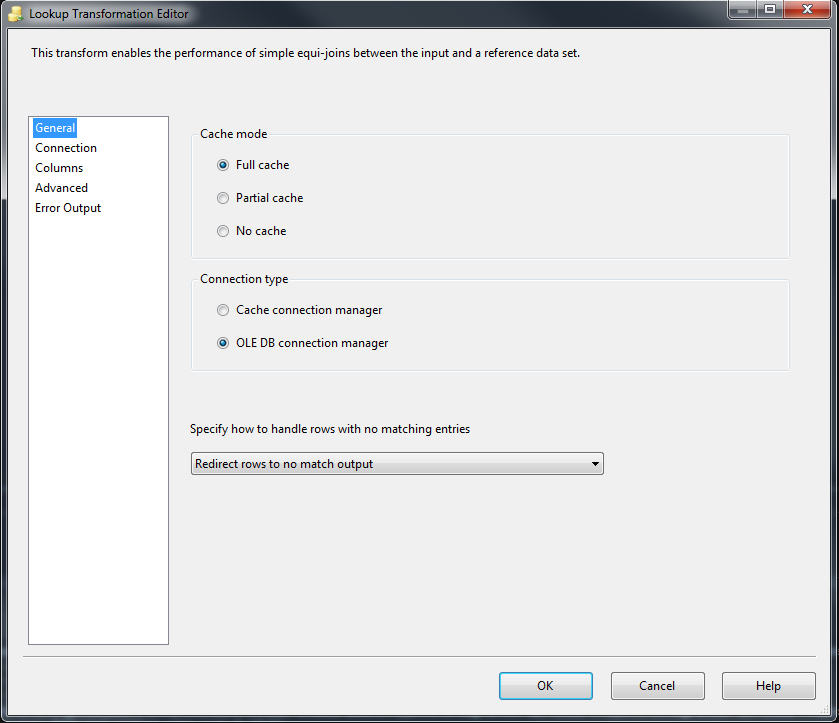
This is a classic case for using LookUp Transformation. First, use a OLE DB Source to get data from the first database. Then, use a LookUp Transformation to filter this data-set based on the ID values from the second data-set. Here is the steps for using a LookUp Transformation:
- In the
Generaltab, selectFull Cash,OLE DB Connection ManagerandRedirect rows to no match outputas shown in the following picture. Notice that usingFull Cashprovides great performance for your package.
General Setting
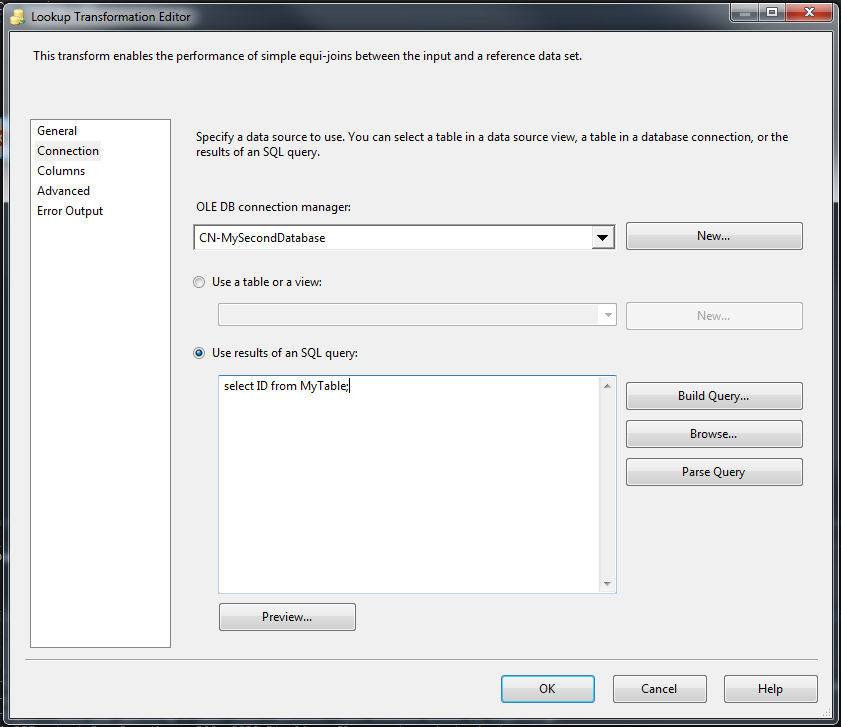
- In the
Connectiontab, useOLE DB Connection Managerto connect to your second server. Then, you can either directly select the data-set withIDvalues or (as is shown in the picture below) you can use SQL code to select the IDs from the filtering data-set.
Connection:
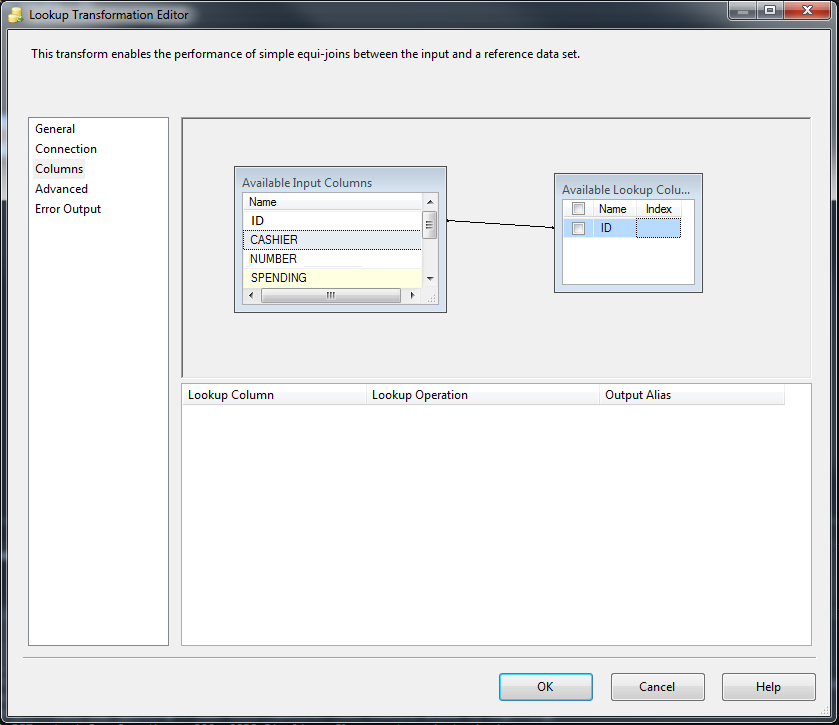
- Go to
Columnstab and selectIDcolumns from the both datasets. For each record from your first data-set, it will check to see if itsIDis in theAvailable LookUp Column. If it is, it will go to theMatchingoutput, else toNo Matchingoutput.
Match ID columns:
- Click on
OKto close theLookUp. Then you need to select theLookUp Match Output.
Match Output:
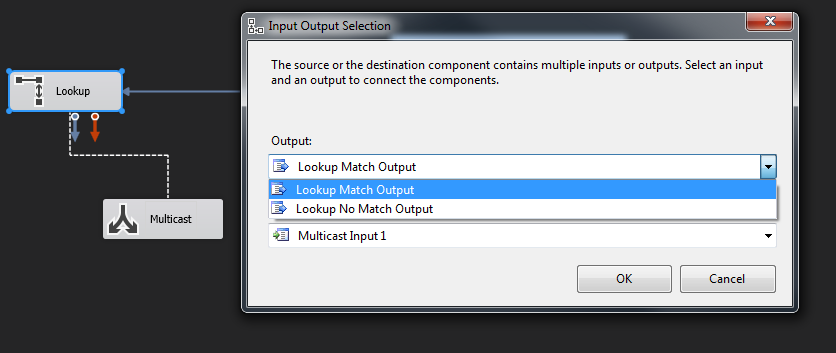
Thank you. @TheEsisia: ID in myFirstDB is int, and ID in mySecondDB is varchar(20). So, I created a derived column with expression (DT_STR,20,1252)id. In the Lookup, I connected "Derived Column.ID" from Available Input Columns to ID in the Available Lookup Columns. I also select the list of columns from Available Lookup Columns to show in the result. When I run the package, I get error "Row yielded no match during lookup." –
Bohannon
In the Look Up transformation, in the Connection tab, select 'use result of a SQL query'. Write a select statement to query the table, but for the ID comulm, use a CAST statement to convert the VARCHAR(20) into int. –
Symposium
performance wise, lookup is not recommended in this case, it is better to filter datain the OLEDB Source –
Enthusiasm
@Enthusiasm First of all, Look Ups use cashing and therefore have great performance. Second, how you are going to filter data in the OLE DB Source when the two datasets are in two different servers? –
Symposium
@TheEsisia use an execute sql task to get the list of ID and store it in a variable (ex:
1,2,3), build the sql command as expression in another variable "SELECT * FROM .... WHERE ID IN(" + @[user::variable] + ")" and use this variable as source in OLEDB SOURCE –
Enthusiasm @TheEsisia i upvoted your answer because my first method started from yours. Thx and good luck –
Schmaltzy
The "best" answer depends on data volumes and source systems involved.
Many of the other answers propose building out a list of values based on clever concatenation within SQL Server. That doesn't work so well if the referenced system is Oracle, MySQL, DB2, Informix, PostGres, etc. There may be an equivalent concept but there might not be.
For best performance, you need to filter against the second db before any of those rows ever hit the data flow. That means adding a filtering condition, as the others have suggested, to your source query. The challenge with this approach is that your query is going to be limited by some practical bounds that I don't remember. Ten, one hundred, a thousand values in your where clause is probably fine. A lakh, a million - probably not so much.
In the cases where you have large volumes of values to filter against the source table, it can make sense to create a table on that server and truncate and reload that table (execute sql task + data flow). This allows you to have all of the data local and then you can index the filter table and let the database engine do what it's really good at.
But, you say the source database is some custom solution that you can't make tables in. You can look at the above approach with temporary tables and within SSIS you just need to mark the connection as singleton/persisted (TODO: look this up). I don't much care for temporary tables with SSIS as debugging them is a nightmare I'd not wish upon my mortal enemy.
If you're still reading, we've identified why filtering in the source system might not be "doable", even if it will provide the best performance.
Now we're stuck with purely SSIS solutions. To get the best performance, do not select the table name in the drop down - unless you absolutely need every column. Also, pay attention to your data types. Pulling LOB (XML, text, image (n)varchar(max), varbinary(max)) into the dataflow is a recipe for bad performance.
The default suggestion is to use a Lookup Component to filter the data within the data flow. As long as your source system supports and OLE DB provider (or you can coerce the data into a Cache Connection Manager)
If you can't use a Lookup component for some reason, then you can explicitly sort your data in your source systems, mark your source components as such, and then use a Merge Join of type Inner Join in the data flow to only bring in matched data.
However, be aware that sorts in source systems are going to be sorted according to native rules. I ran into a situation where SQL Server was sorting based on the default ASCII sort and my DB2 instance, running on zOS, provided an EBCDIC sort. Which was great when my domain was only integers but went to hell in a handbasket when the keys became alphanumeric (AAA, A2B, and AZZ will sort differently based on this).
Finally, excluding the final paragraph, the above assumes you have integers. If you're performing string matching, you get an extra level of ugliness because different components may or may not perform a case sensitive match (sorting with case sensitive systems can also be a factor).
I would first create a String variable e.g. SQL_Select, at the Scope of the Package. Then I would assign that a value using an Execute SQL Task against the 1st database. The ResultSet property on the General page should be set to Single row. Add an entry to the Result Set tab to assign it to your Variable.
The SQL Statement used needs to be designed to return the required SELECT statement for your 2nd database, in a single row of text. An example is shown below:
SELECT
'SELECT * from MySecondDB WHERE ID IN ( '
+ STUFF ( (
SELECT TOP 5
' , ''' + [name] + ''''
FROM dbo.spt_values
FOR XML PATH(''), TYPE).value('(./text())[1]', 'VARCHAR(4000)'
) , 1 , 3, '' )
+ ' ) '
AS SQL_Select
Remove the TOP 5 and replace [name] and dbo.spt_values with your column and table names.
Then you can use the variable SQL_Select in a downstream task e.g. an OLE DB Source against database 2. OLE DB Sources and OLE DB Command Tasks both let you specify a Variable as the SQL Statement source.
Thank you all. I use the 2nd solution from Hadi –
Bohannon
You could add a LinkedServer between the two servers. The SQL command would be something like this:
EXEC sp_addlinkedserver @server='SRV' --or any name you want
EXEC sp_addlinkedsrvlogin 'SRV', 'false', null, 'username', 'password'
SELECT * FROM SRV.CatalogNameInSecondDB.dbo.SecondDBTableName s
INNER JOIN FirstDBTableName f on s.ID = f.ID
WHERE f.ID IN (list of values)
EXEC sp_dropserver 'SRV', 'droplogins'
© 2022 - 2024 — McMap. All rights reserved.