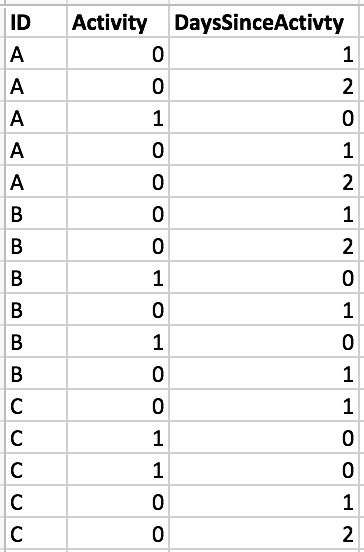
We using a new para 'G' here
df['G']=df.groupby('ID').Activeity.apply(lambda x :(x.diff().ne(0)&x==1)|x==1)
df.groupby([df.ID,df.G.cumsum()]).G.apply(lambda x : (~x).cumsum())
Out[713]:
0 1
1 2
2 0
3 1
4 2
5 1
6 2
7 0
8 1
9 0
10 1
11 1
12 0
13 0
14 1
15 2
Name: G, dtype: int32
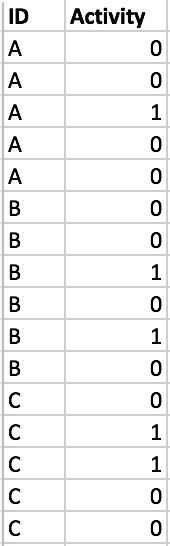
Data input
df=pd.DataFrame({'ID':list('AAAAABBBBBBCCCCC'),'Activeity':[0,0,1,0,0,0,0,1,0,1,0,0,1,1,0,0]})
Explanation :
Here we get the new para 'G'
df['G']=df.groupby('ID').Activeity.apply(lambda x :(x.diff().ne(0)&x==1)|x==1)
df
Out[134]:
Activeity ID G
0 0 A False
1 0 A False
2 1 A True
3 0 A False
4 0 A False
5 0 B False
6 0 B False
7 1 B True
8 0 B False
9 1 B True
10 0 B False
11 0 C False
12 1 C True
13 1 C True
14 0 C False
15 0 C False
Then we do cumsum for G, is to getting where is the cycle we should set the number to 0
df.G.cumsum()
Out[135]:
0 0
1 0
2 1
3 1
4 1
5 1
6 1
7 2
8 2
9 3
10 3
11 3
12 4
13 5
14 5
15 5
Name: G, dtype: int32